Follow-me Algorithm¶
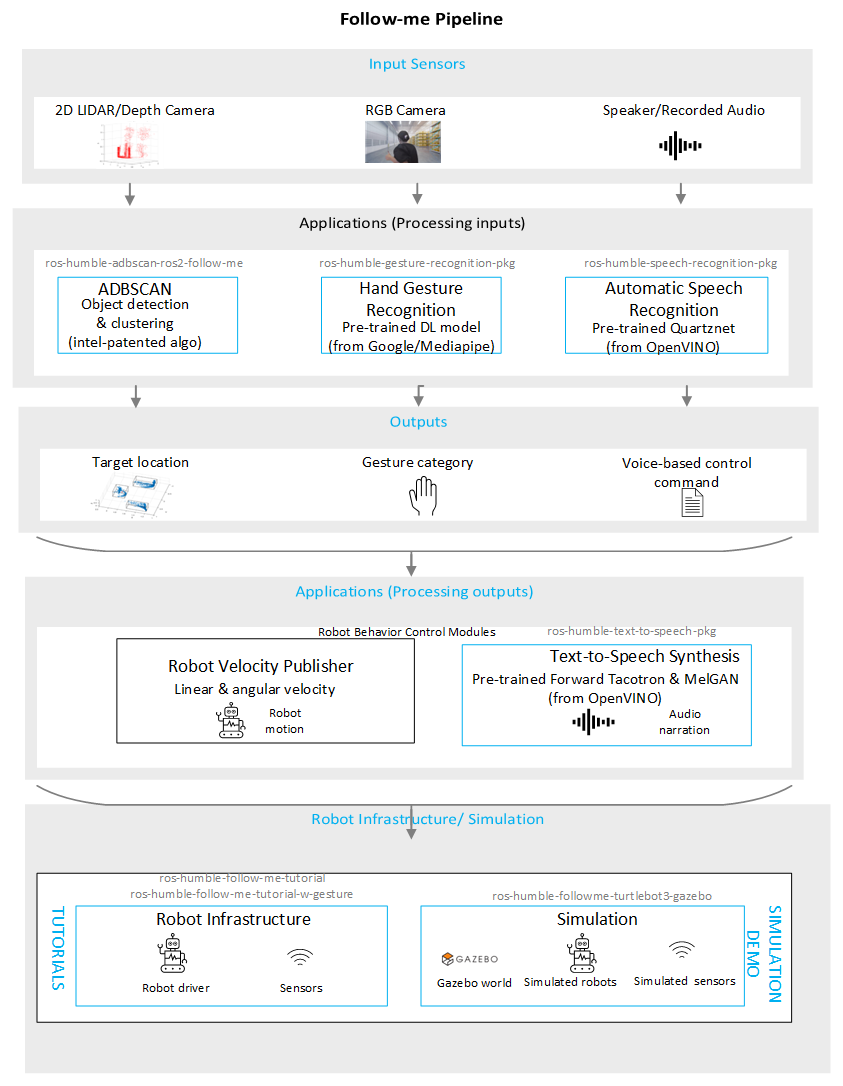
The Follow-me algorithm is a Robotics SDK application for following a target person without any manual or external control dependency. The complete pipeline is described here. A comprehensive diagram of the application is showed in the figure below. The Deb packages are outlined with blue rectangles in the figure.
Applications (processing inputs)
This multimodal solution can control robot motion by any combination of the following three factors:
Target person’s proximity/location: We use an Intel®-patented point cloud-based object detection and localization algorithm, called ADBSCAN, for this purpose. It takes point cloud data as inputs from a 2D LIDAR or RGB-D camera and outputs the presence and location of the target (to be followed). ros-humble-adbscan-ros2-follow-me package launches this node. This module is present in all versions of the Follow-me algorithm.
Hand gesture of the target: An open-source deep learning model, developed by Google’s Mediapipe framework, is used for the target person’s hand gesture recognition from RGB image. See Mediapipe Hands for more details of the model. ros-humble-gesture-recognition-pkg subscribes to the RGB image and publishes ROS 2 topic with gesture category msg.
Voice command: A pre-trained neural network, called Quartznet, is used for automatic speech recognition and convert the target person’s voice commands into robot motion control commands. The pre-trained Quartznet parameters are obtained from OpenVINO™ model zoo. ros-humble-speech-recognition-pkg launches this node and publishes ROS 2 topic with voice-based robot control commands.
Applications (processing outputs)
The outputs of all or a combination of the above modules are used to determine robot’s velocity and publish twist msg, which can be subsequently used by a real robot or a simulated robot in Gazebo.
The demos on real robots and simulation environments are referred to as Tutorials and Simulation Demos respectively. You can navigate to each of these categories using the following links:
The demo with audio control contains an additional node (ros-humble-text-to-speech-pkg) containing a text to speech synthesis module to enable audio narration of the robot’s activity during the course of its movement. This module uses pre-trained text-to-speech synthesis model, called Forward-Tacotron from OpenVINO™ model zoo.
Note
Please display a disclaimer/signage/visible notice to the surrounding people stating the use of voice-activated/gesture recognition technology while the follow-me application with audio and/or gesture is in use.
Also please keep in mind that the accuracy of the speech recognition model may vary depending on the user demography. We recommend that any application using follow-me with audio control to undergo bias testing (dependence on the voice of the user demography) appropriate to the context of use.